Genesis of Google's Web Ranking Dynasty
A Deep Dive into the Mathematics and History Behind the Technology That Changed Search Forever

Hi, glad you landed on this blog. I am Arnab Sen, a Software Engineer at Google. In our previous blog, we delved into the intriguing world of Graph Databases and their inner workings. Today, we'll take a detour from the technical details to explore a practical application of Graphs – PageRank, the algorithm that powers Google Search!
Introduction
Imagine the internet before Google. It was a bit like a sprawling, uncharted territory. When Sir Tim Berners-Lee first created the World Wide Web, he actually kept a list in the back of his notebook, of which new websites that came online.

Then search engines emerged to make it easy to find relevant websites. Early search engines like Yahoo! relied on humans to categorize websites, resulting in often inaccurate or incomplete results.

Searching for information was a tedious and often frustrating process. It was clear that a better way was needed to navigate the ever-growing expanse of the web.

Enter Larry Page and Sergey Brin, two Stanford PhD students with a radical idea. They envisioned a search engine that would rank websites not just by keywords, but by their importance and relevance within the vast network of the web. This was the birth of PageRank, a trillion dollar algorithm that would propel Google to become the dominant force it is today.

Link to the paper: The PageRank Citation Ranking
Mapping the Web
Most webpages link to other relevant webpages. For example, this page links to the original paper. When the paper was written, the web had 150 million pages and 1.7 billion links. Each page can be seen as a node, and the links as edges connecting one node to another.
So, if webpages A and B links to webpage C it should look something like this:
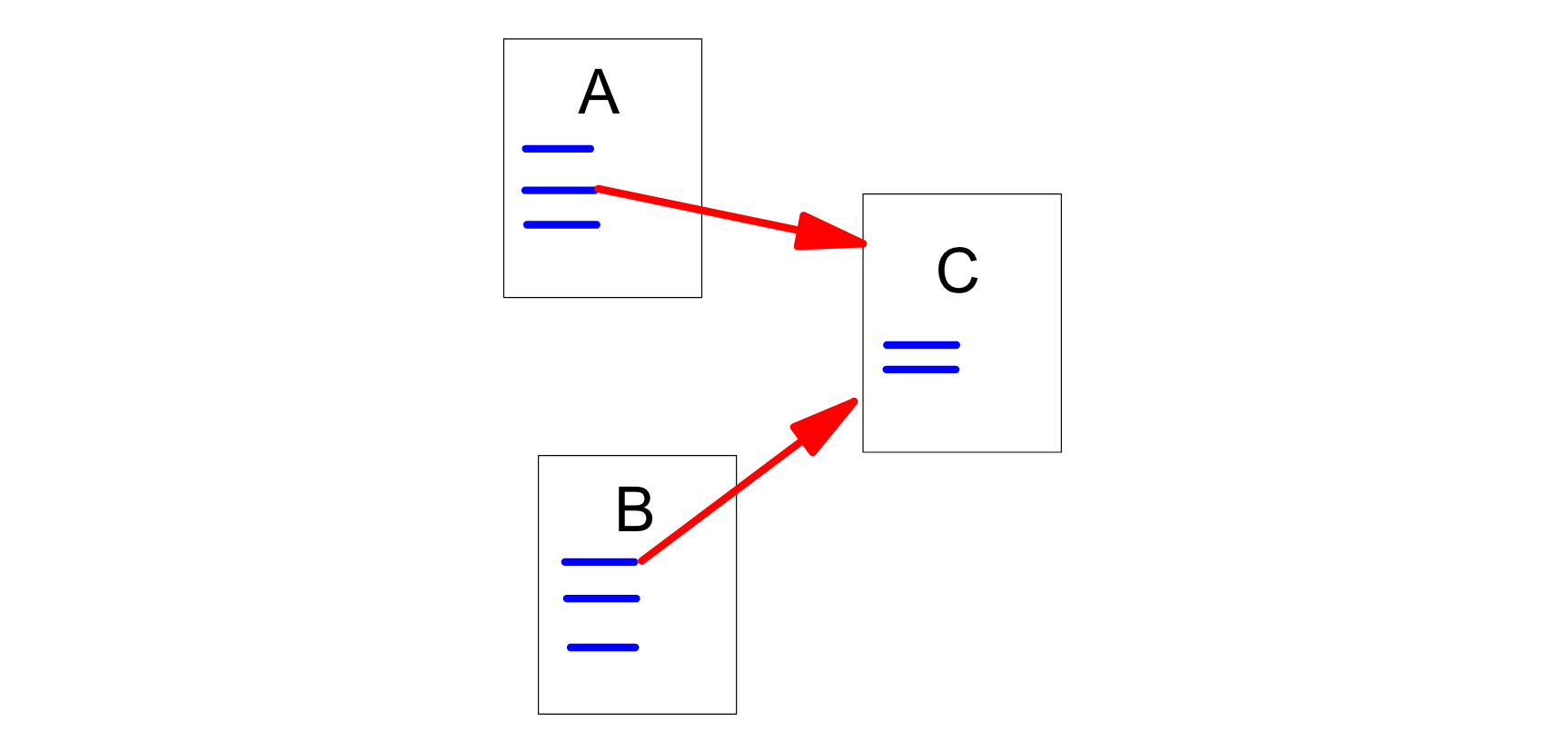
Here A and B are called backlinks of C.
Why are these backlinks important? The idea is that "highly linked pages are more important than pages with few links." For example, many blogs and articles about PageRank will link to the original paper, supporting the hypothesis that the original paper is more important. This is similar to citations in academic research; usually, the more impactful a publication is, the more it gets cited.
Another observation the authors pointed out is that any outgoing links from these relatively important pages should also be given higher importance. PageRank tries to determine how well the importance of a page can be estimated from its link structure.
PageRank's brilliance lies in its smart use of a mathematical concept called the Markov Chain.
Mathematically, a Markov Chain is a model that describes a sequence of possible events where the probability of each event depends only on the state attained in the previous event. It's like a random walk where your next step is determined by a set of probabilities associated with your current location.
First, let's understand how the author of the papers defines PageRank.
Defining PageRank
If a webpage A has 4 outgoing links, the Rank(A) is divided equally among the 4 links. So, if webpage C has backlinks from 2 different webpages, then the Rank(C) will be the sum of the ranks from each link.
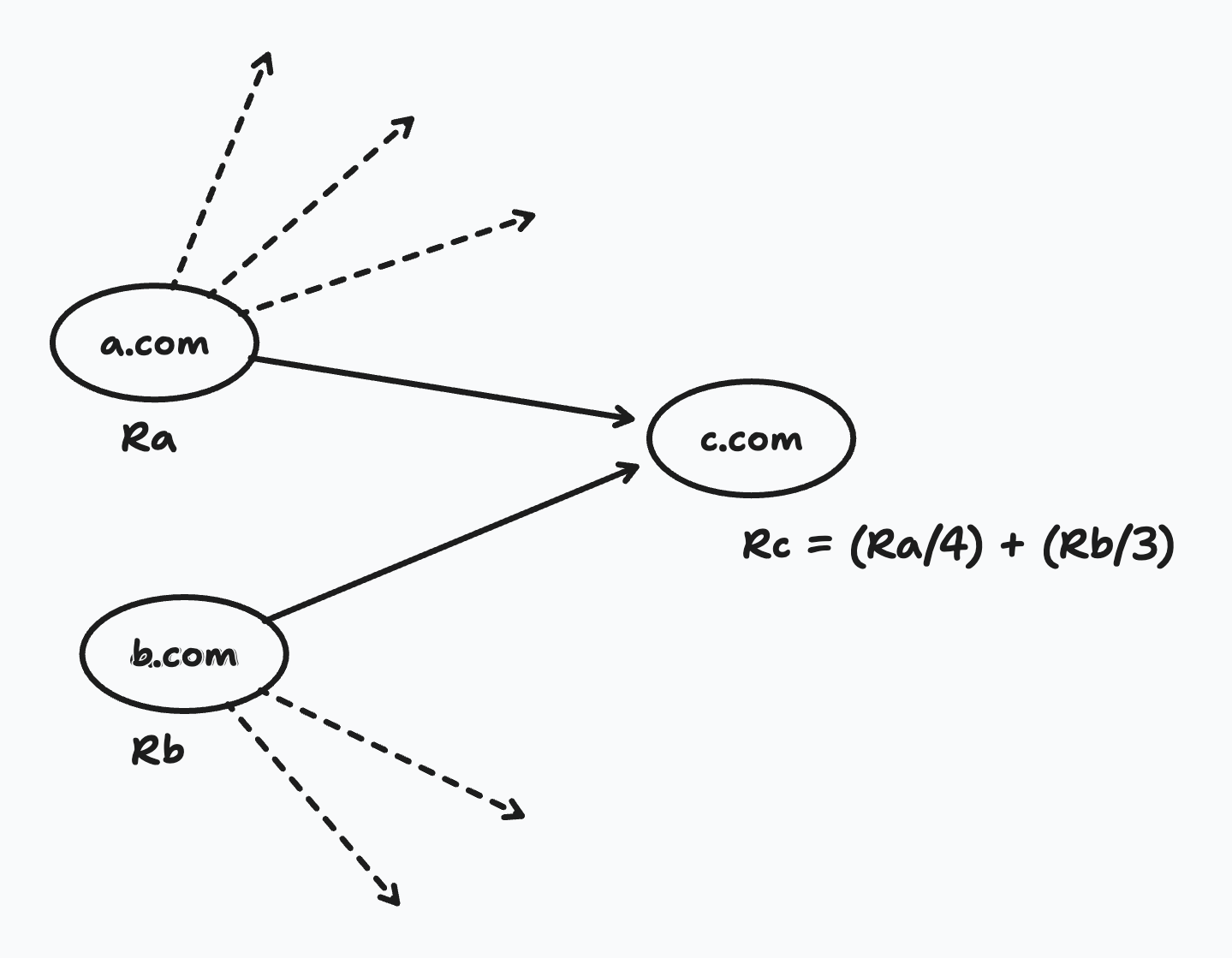
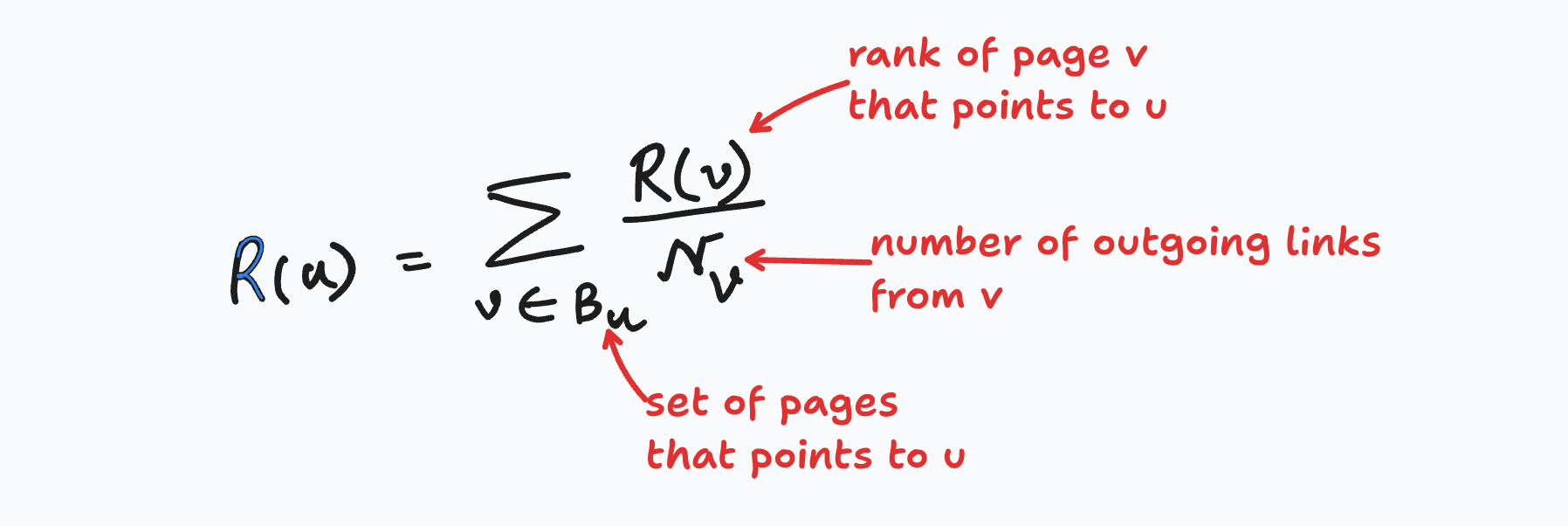
More formally:
The paper includes a constant factor but let's keep things simple for now.
But then how do we get the Ranks of a.com and b.com? Well, we do the same process, recursively.
What if there is an outgoing link from c.com to a.com? Then once we get the rank of c.com we have to recompute the rank of a.com? This is a stochastic process, and we can use the mathematical model of Markov Chains for that.
And the PageRank formula described above can be represented using matrices as follows. At any point we can define A as a square matrix with the rows and columns corresponding to the web pages.
if (page u and v are connected):
A[u][v] = 1/N[u]; // N(u): is the number of outgoing links from u
else:
A[u][v] = 0
If R is a vector over all the webpages then we can describe it as:
R = cAR
Here c is a normalization factor, to ensure that the total rank of all webpages is constant. And we can keep computing this until we don’t see any change in the value of the vector R. That final value is called the Stationary Distribution of a Markov Chain. But will that always exist? To know we first have to understand a few more terms:
Reducible Markov Chains
A Markov chain is considered reducible if its states can be divided into two or more disjoint sets, where it's impossible to move from one set to another. In other words, there are "barriers" within the chain that prevent transitions between certain groups of states.
Periodic Markov Chains
A Markov chain is considered periodic if there is a fixed pattern or cycle in the way it revisits certain states.
In both these cases, finding a stationary distribution becomes tricky.
Problem of Rank Sink
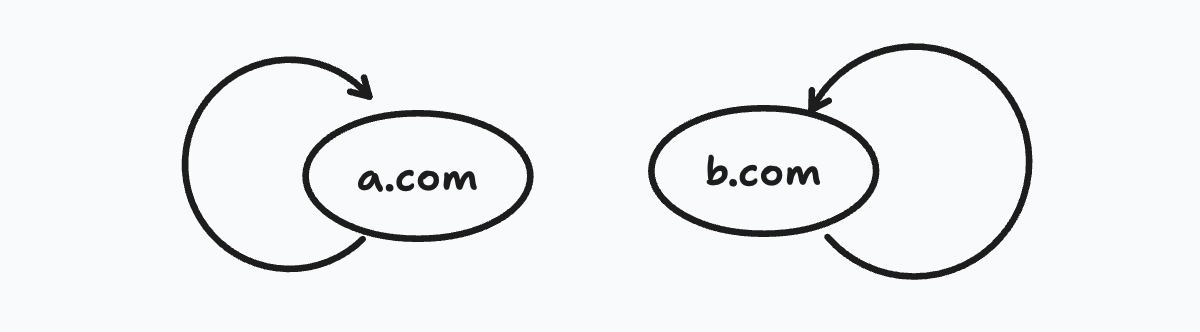
But we have another problem. Consider this case, b.com points to a.com. But a.com points only to c.com and c.com points only to a.com.
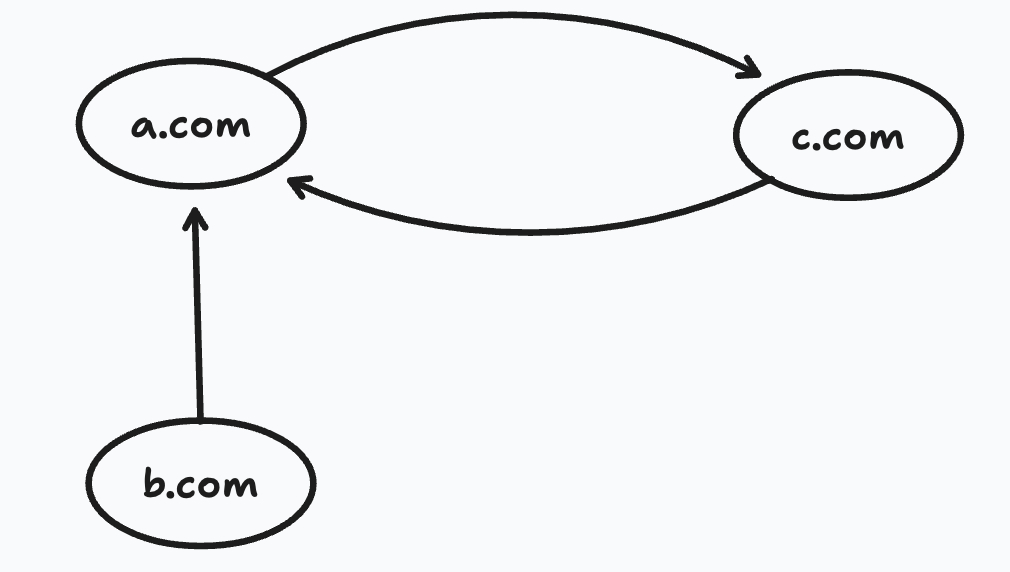
What will eventually happen is all the rank from the entire chain will get trapped in this cycle b/w a.com and b.com. The loop forms a trap which is called the rank sink.
The authors tackled these ingeniously by a method called...
Random Surfer Model
Sounds fancy, but it's simple. Just think from what you would do in such a scenario. If you visit a webpage that has just one link to another webpage, and that page then links to the original webpage. Will you keep clicking and going in loops? Obviously not, you will just go to a different page. This is what a random surfer model will do. Occasionally a random surfer will get bored and then jump to a random page chosen based on a distribution.
This super simple solution is enough to tackle all the problems we described above.
Mathematically, we can assume that there is an outgoing node from every node to every other node. And then to compensate for this extra link, we can tweak the factor c to again normalize the metrics.
Let's dive into the Implementation
So, there are two parts of this search engine problem. First we need to have the database of all the links to create the Markov Chain in the first place. This is done by a program called Crawler.
Then comes the actual PageRank implementation. And here the steps:
Convert each URL to an unique integer ID and store the mapping in a database.
Sort the link structure by Parent ID.
Remove all the dangling links. (Dangling links are those pages that have no outgoing link. Removing these links have no effect on the final distribution)
Have an initial assignment of ranks.
- The initial assignment won’t really affect the final results as we saw that Ergodic Theorem guarantees an unique stationary distribution, but it will affect how quickly we can reach the final state i.e the rate of convergence.
The original implementation used single precision floating point values at 4B each. So, for 75 million URLs it amounted to 300 MB.
- In terms of scalability, if a point comes where memory available is insufficient to hold the weights, the previous weights can be stored in disk and then accessed linearly.
Finally once convergence is reached, the dangling links are attached back.
When the paper was released this whole process took around 5 hrs.
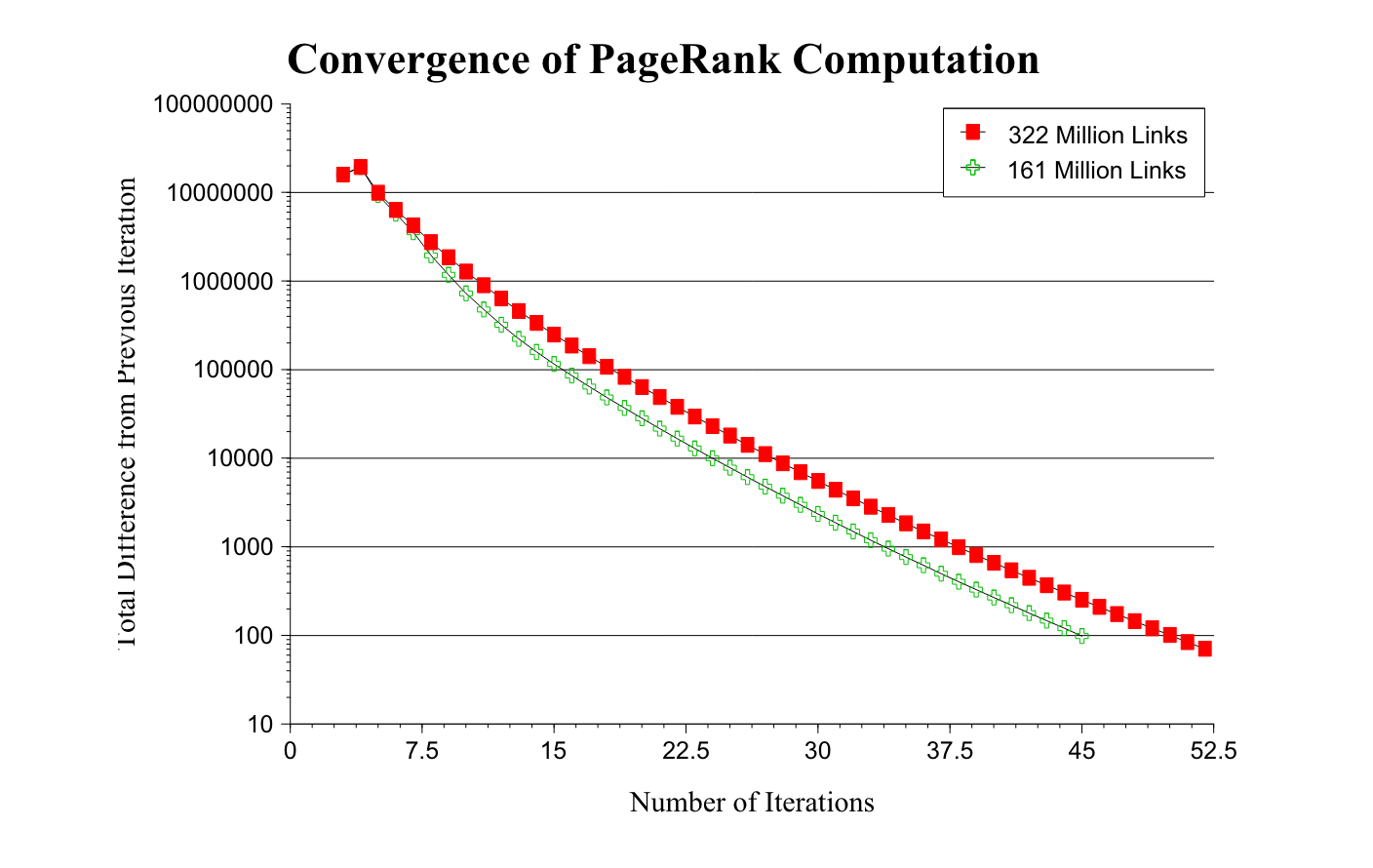
On a large 322 million link database the convergence took around 52 iterations. The convergence on half the data took around 45 iterations, which shows that this PageRank algorithm can scale very well even for large collections as the scaling factor is roughly linear in logn. The authors admitted that the cost required to compute the PageRank is far insignificant compared to the cost required to build a full text index.
Early Results
To initially test the usefulness of PageRank the authors implemented a search engine which used just 16 million web pages and performed just title based search and then sorted the results by PageRank.
Here is an example of the search result for the term “University”. On the left we have the PageRank algorithm and on the right we have another popular search engine at that time, Altavista.
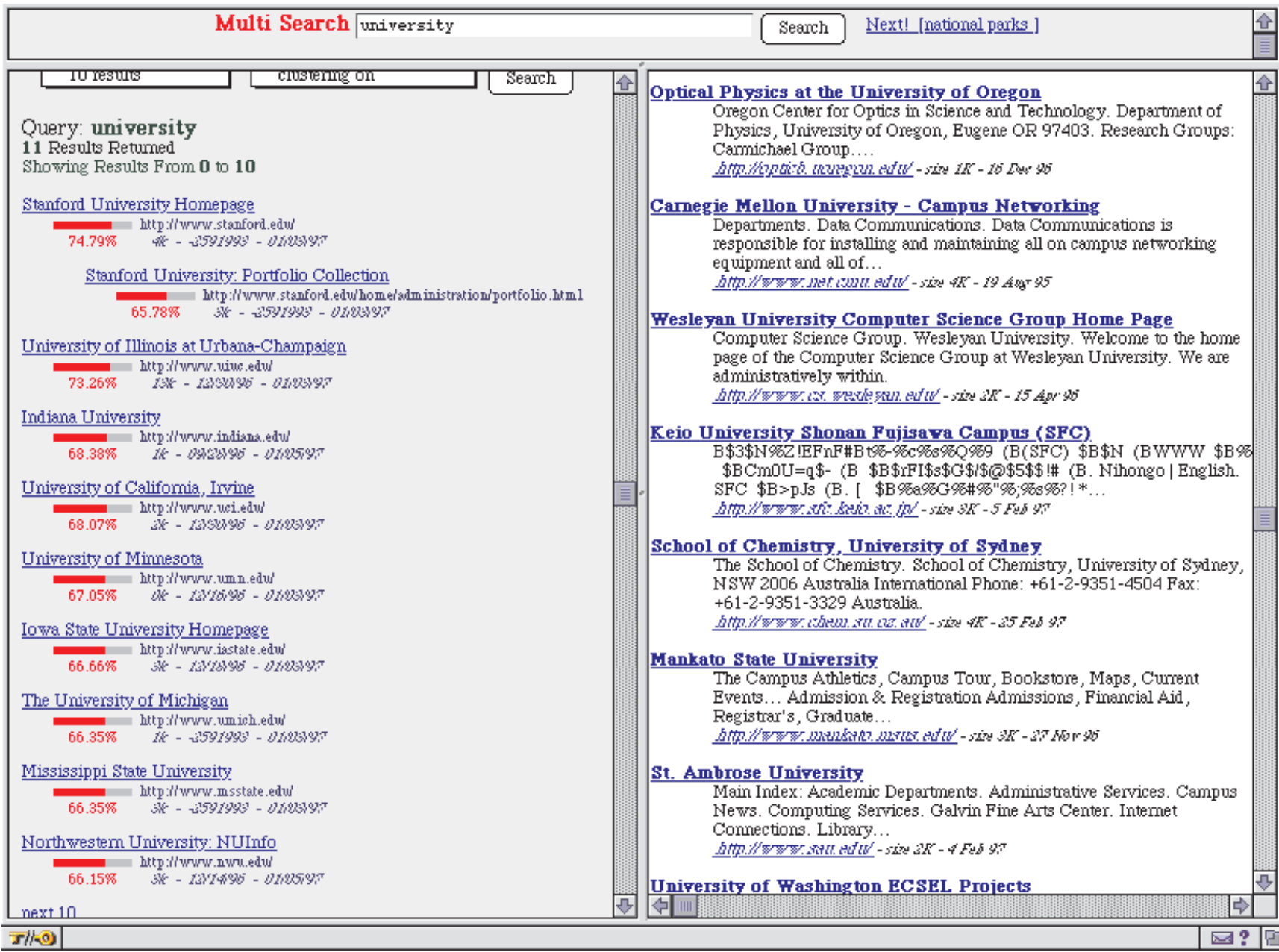
PageRank returns the home page of Stanford as the top result (since the initial PageRank was built from Stanford, it is understandable that most webpages had outgoing links to the Stanford homepage). You can also see the PageRank value normalized to 100% as the red progress bar next to each link. In contrast, Altavista returned random-looking webpages that matched the query "University."
The story behind the name
BackRub was the initial name given to the search engine that would later become Google. The name "BackRub" actually reflects the core mechanism behind the search engine's algorithm, can you guess?
Yes, "backlinks".
The name "BackRub" was eventually dropped in favor of "Google" in 1997. The new name was inspired by the mathematical term "googol," which represents the number 1 followed by 100 zeros, symbolizing the vast amount of information that the search engine aimed to organize and make accessible.
In one of the blogs published by Google in 2008, they mentioned that “by 2000 the Google index reached the one billion mark. Recently, even our search engineers stopped in awe about just how big the web is these days -- when our systems that process links on the web to find new content hit a milestone: 1 trillion (as in 1,000,000,000,000) unique URLs on the web at once!”.
Conclusion
The tale of PageRank is a fascinating journey through the early days of the web, where two Stanford PhD students laid the foundation for what would become the world's most powerful search engine.
I'm still constantly amazed by the sheer scale at which this algorithm operates, processing trillions of webpages and billions of searches every day. PageRank's legacy continues to shape how we access information, discover new ideas, and connect with others across the globe.
I hope this exploration into the inner workings of PageRank has shed light on the brilliance behind this groundbreaking algorithm. It's a story of how a simple idea, combined with rigorous mathematical principles, revolutionized the way we navigate the vast landscape of the World Wide Web which we kind of take for granted.
If you like my blogs, do follow me and subscribe to my newsletter for more such informative bits.



