Row, Row, Raft Your Nodes: A Guide to Consensus in Distributed Systems
Understanding the Raft Consensus Algorithm and how to achieve harmony in distributed systems on a very high level.

Introduction
I have been recently diving into the world of Distributed systems and I came across a rather interesting paper: "In Search of an Understandable Consensus Algorithm". What caught my attention was the paper's primary objective of creating a consensus algorithm that is easy to understand. Typically, in the realm of new research, we tend to emphasize factors like efficiency, correctness, and conciseness while overlooking how accessible a concept is for others to grasp and apply in practical scenarios.
We often neglect how easy it for someone is to grasp the concept and use it to build practical stuff or solve real problems. Sometimes we do the opposite, if something works but is very hard to understand and is confusing we consider it to be very "clever" and end up rewarding complexity. That's why I appreciate the approach taken by the authors, Diego Ongaro and John Ousterhout, in prioritizing the algorithm's comprehensibility.
With many major corporations transitioning to distributed systems, having an algorithm that is both easy to understand and intuitive can empower developers to create systems more seamlessly and devise more efficient implementations."
So, what is Consensus
Let's start with a simple analogy:
You have been invited to a party and you have dressed up all nice and good. Then you ask your 4 friends if you are looking good (if you don't have so many friends just imagine you do, at this point, you must be good at it). Two of them say that you are looking good, and the rest say you are not. What are you supposed to do?

But if 3 of them said that you do look good (quite unusual right?) then you can go with the majority decision.
This is consensus !!
In distributed systems, we know that we have multiple nodes, and consensus refers to coming to an agreement.
Consensus simply means to get all the nodes in distributed computing to agree on a common value or decision, despite the presence of faults, delays, or unreliable communication. This agreement is crucial for ensuring that the distributed system functions correctly and consistently.
Even though it sounds simple, many broken systems have been built in the mistaken belief that this problem is easy to solve.
There is a pattern in most of the fault-tolerant systems. For example, in MapReduce, the computation is replicated but the whole thing is controlled by a single master. Similarly, we have GFS which replicates the data and has a single master to determine who the primary is for the piece of data. The benefit of having such a single master system is that there will be no disagreement. But at the same time, it makes it a single point of failure. So we need some sort of consensus to avoid such failures.
History of Consensus Protocols
Well, now that I think "history" is an overstatement cause there is just one very popular protocol called "Paxos" which has been the gold standard for a long long time. First submitted in 1989 by the Leslie Lamport, the Paxos protocol is named after a fictional legislative consensus system on the island of Paxos in Greece.

FYI Leslie Lamport was the creator of LaTeX. He also won the Turing Award which is like the Nobel Prize for Computer Science.
The problem with Paxos was it was really hard to wrap our minds around. It only solved a portion of the problem and hence made it difficult to build systems around Paxos.
Raft Algorithm
As mentioned before the authors' primary design goal when building Raft was "understandability".
Now this doesn't mean that Raft is very very easy to understand, there are still a lot of intricacies and edge cases to cover, but I will try my best to give a brief overview of the entire thing. So let's start.
What are we dealing with?
We have a client, which can be a user or a service etc. And it tries to fetch some data from the server we have which is nothing but a cluster of nodes.
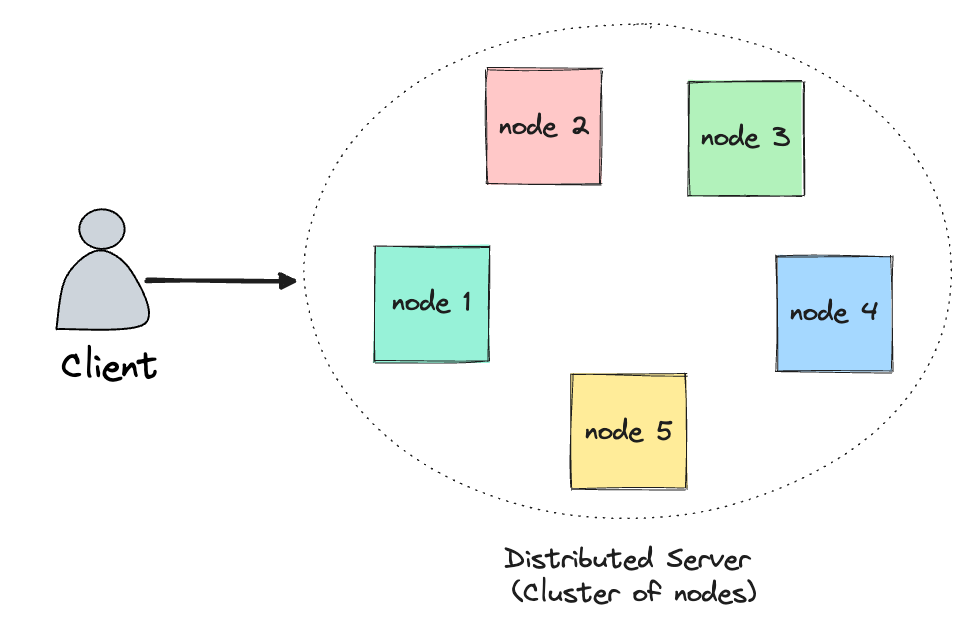
Now, to ensure consensus we need the nodes to agree on a particular value and then send that to the client.
How do we ensure that all the nodes have the same value? Raft achieves that through something called a "Replicated Log".
It ensures that all the commands (or operations) that need to be performed are replicated across the nodes in the same order. So, let's say you have a variable X initially, the value is 0 and then you perform some operations like:
add 5mul 10sub 15
If these commands were logged in the same order then the final value of X will be the same for all the nodes assuming the fact that the operations in the nodes (which are also referred to as state machines) are deterministic.
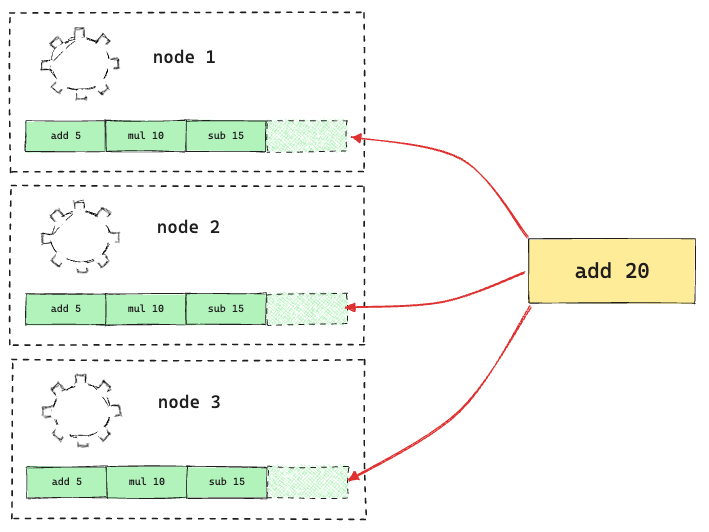
So, when a new command gets proposed, it first gets logged on all the nodes (at least most of the nodes) at the end of their logs. Only when the log gets properly replicated, does the node perform its computation and send the result to the original client.
The idea behind this is if the logs get replicated properly the cluster can continue functioning as long as the majority of the nodes are up (Yes, it's more like democracy, the majority wins).
Who will instruct the nodes on what to do?
Again similar to democracy, here also we have a leader node elected by other nodes. The leader node is responsible for talking to the client, giving commands to the other nodes, etc.
Before diving deep into the functioning of the leader let's see how the nodes become a leader.
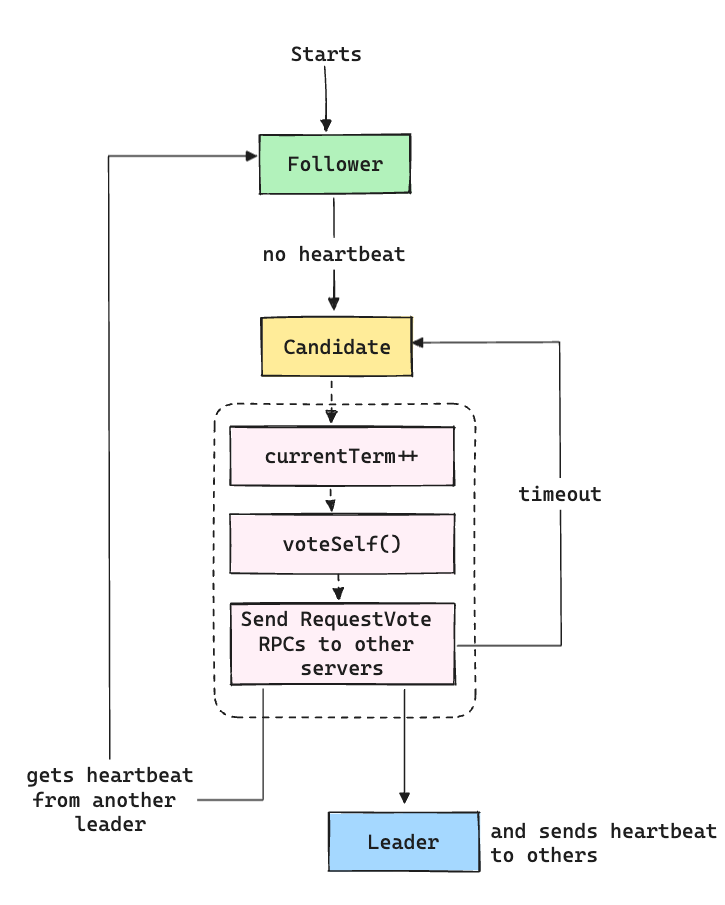
Server States
The nodes/server have 3 states:
Follower
Candidate
Leader
In normal service, there will be just one Leader and all the other servers will be Followers.
Followers are passive, they issue no requests and can only respond to requests from Leaders and Candidates.
The Leader handles all the client requests. It also sends regular heartbeats (empty requests) to the Followers to maintain authority. More like it's saying "Don't get too excited, I am still your leader".
If a Follower receives no communication over a time period (called election timeout) it assumes that no Leader is available and starts the process of Leader Election.
Leader Election
Let's talk about term before diving into Leader Election. To have consensus we need to have a mechanism to detect obsolete information. Like if a particular server was a leader and then it stopped responding, and a new leader was appointed. We need to ensure that the other servers don't take instructions from the old leader anymore. Raft achieves this by dividing the time into terms or arbitrary lengths called term.
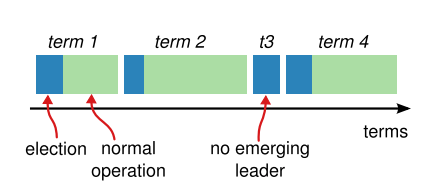
Each term starts with an election of the leader and then if the election is successful the leader rules for some period of time which is represented in green in the above diagram.
You can see how this is similar to the administrative process of a country where each leader has a term like 5 years and then post that election happens to elect a new leader.
In Raft, now the interesting thing is there is no global concept of term among the servers. Each server starts with its own terms.
When the election process starts the follower increments its current term index and becomes a candidate. It votes itself and then sends specific requests to the other nodes requesting to be a leader in other words asking for their vote. This happens by a special kind of request called RequestVote RPCs.
Whenever the server communicates with the other it includes what it thinks the current term index is. Then the other server responds by including its term index.
Now if there is a mismatch the server with the lower-term starts having an identity crisis and falls back to being a follower. And the other server just ignores it.
A Server is entitled to vote only one server and that happens on a first come first serve basis. So by the end of the process, the Candidate server with the most votes becomes the leader and then sends heartbeat messages to all of the other servers to establish its authority and prevent new elections.
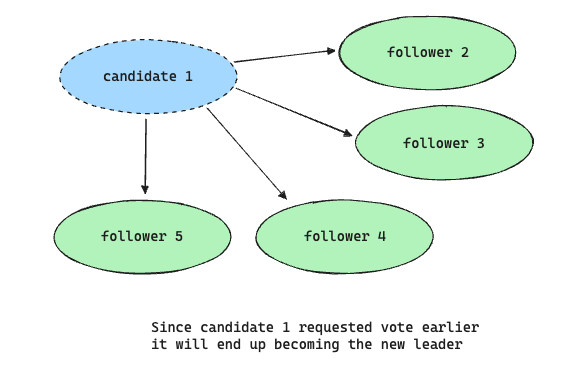
Here I had a doubt, what if all the server realizes that the leader no longer exists or the current term is over, votes themselves, and requests a vote at the same time? They will just end up waiting indefinitely to get majority votes. Or what if two candidates receive the same number of votes (this is called a split vote)?
Raft solves this by using randomized election timeouts, which means election timeouts are chosen randomly from a fixed interval (e.g., 150-300 ms). This way in most cases only one server will timeout at a time, become a candidate, and will request a vote before the other server times out. Even in case of a split vote, each candidate restarts its randomized election timeout at the start of an election and it waits for that timeout to elapse before starting the next election. This randomness drastically reduces the chances of another split vote.
How does the normal operation happen?
Let's go through how a normal operation will take place with consensus in Raft.
First, the client sends a command to the leader. Wait, how will the client know who the leader is? Well, the client can send it to any server and if the server is a follower it will simply redirect it to the leader.
The Leader appends the command to its log and sends another request (called AppendEntries RPC request to all its followers). The followers on receiving this request just append the new log to their existing logs record. Note, at this point they just append it and don't actually perform any computation. It's the leader who decides when it is safe to apply the log entry i.e. when the entry has to be committed. This is actually called 2PC (Two Phase Commit).
The append request contains two identifiers, one is the term index which I already mentioned before, and another is the log index which is the position of the new entry in the log. The leaders use these two index values to determine if the majority of the servers have the logs up to date and then issue a commit.
In any case, the logs become inconsistent, the leader forces the followers to duplicate the leader's log. To bring a follower’s log into consistency with its own, the leader finds the latest log entry where the two logs agree, deletes any entries in the follower’s log after that point, and sends the follower all of the leader’s entries after that point.
This is how the Leader ensures that every server (or at least the majority) has the same order of the logs i.e. consensus is reached, performs the computation, and then responds to the client.
This is how we can build a system with high data consistency with Raft and many distributed consistent database like CockroachDB uses Raft.
This was a very brief overview of Raft. There are many more aspects to this that couldn't be covered in a blog and I urge you to go through the original paper. I hope you found my blog useful. If you have any feedback share it in the comments. You can sign up for the Hashnode newsletter to get notified every time I post a blog. Learn more about me at arnabsen.dev/about. Have a nice day.




